Entity Framework generates single queries using JOINs for related entities. JOINs can create significant performance issues in some scenarios.
EF can split a single query into a few to eliminate such performance issues.
Let’s look at these performance issues and how splitting queries can resolve them.
Cartesian Explosion
Let’s assume such entity models. There is a Department that can contain lists of Employees and Projects.
public class Employee
{
public int Id { get; set; }
public string Name { get; set; }
public int DepartmentId { get; set; }
}
public class Project
{
public int Id { get; set; }
public string Name { get; set; }
public int DepartmentId { get; set; }
}
public class Department
{
public int Id { get; set; }
public string Name { get; set; }
public IList<Employee> Employees { get; set; } = new List<Employee>();
public IList<Project> Projects { get; set; } = new List<Project>();
}Now, we want to select all Departments, including Employees and Projects.
var departments = context.Departments
.Include(d => d.Employees)
.Include(d => d.Projects)
.ToListAsync();EF generates the following SQL with two LEFT JOINs.
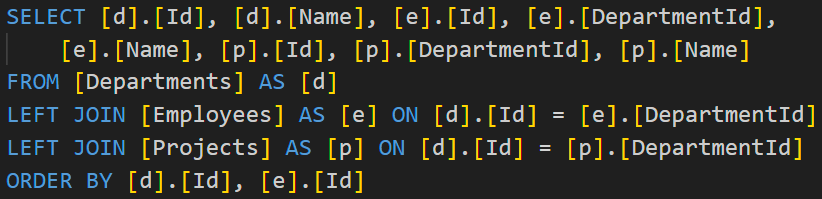
Since Employees and Projects are related collections of Departments at the same level, the relational database produces a cross product. It means that each row from Employees is joined with each row from Projects.
Having 10 Projects and 10 Employees for a given Department, the database returns 100 rows for each Department.
It’s called a Cartesian explosion. It refers to a situation where a query produces an unexpectedly large number of results due to unintended cartesian products (cross joins) between tables.
All this unintended data is transferred to the client. If there is a lot of data in the database or we include even more related data at the same level, the performance issue could be significant.
Note: Cartesian explosion does not occur when two JOINs aren’t at the same level (when you use the ThenInclude method after the Include method).
Query Splitting
Splitting query resolves the issue with the Cartesian explosion. EF generates several separate queries to avoid the problem.
var departments = context.Departments
.Include(d => d.Employees)
.Include(d => d.Projects)
.AsSplitQuery()
.ToListAsync();EF generates three separate queries. The first query selects Departments. The other two include Projects and Employees with INNER JOINs separately.
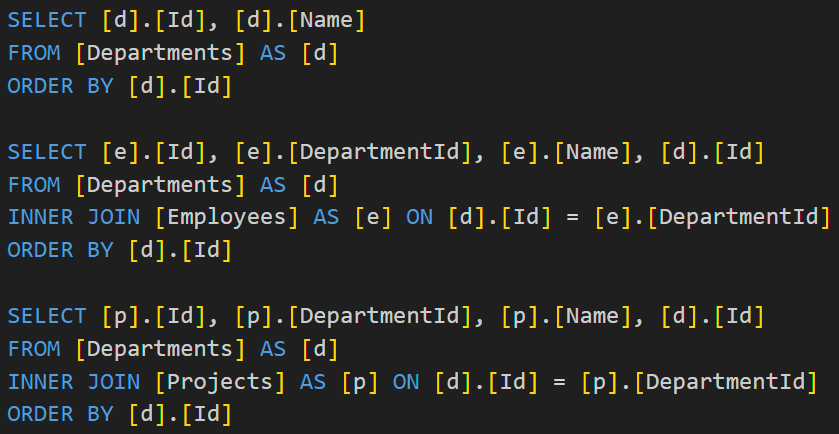
No Cartesian explosion.
However, it’s three separate queries, three round-trips to a database. It can result in inconsistent results when concurrent updates occur. You can use Serializable or Snapshot transaction isolation levels to mitigate the problem with data consistency. However, it may bring other performance and behavioral differences.
Global Query Splitting
You can configure split queries as the default behavior for your database context.
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
=> optionsBuilder
.UseSqlServer("[ConnectionString]",
o => o.UseQuerySplittingBehavior(QuerySplittingBehavior.SplitQuery));With such a configuration, you can still execute specific queries as a single query.
var departments = context.Departments
.Include(d => d.Employees)
.Include(d => d.Projects)
.AsSingleQuery()
.ToListAsync();Data duplication
Let’s go back to our first query, do only one Include, and see the SQL generated by EF.
var departments = context.Departments
.Include(d => d.Employees)
.ToQueryString();SQL:

Department columns (Name column) repeat for every Employee row. This is usually normal and causes no issues.
However, if our Department table has a big column (e.g., binary data, huge text, etc.), then this big column will be duplicated for each Employee row. It can also cause performance issues similar to a Cartesian explosion. A splitting query is also a good choice in such cases.

